코딩 공부/AWS AIML 스페셜 웨비나
SageMaker 실습 내용
Dev_SeokHyeon
2024. 4. 22. 12:23
상세한 소스코드는 아래에서 확인이 가능합니다.
https://github.com/aws-samples/aws-ai-ml-workshop-kr/tree/master
GitHub - aws-samples/aws-ai-ml-workshop-kr: A collection of localized (Korean) AWS AI/ML workshop materials for hands-on labs.
A collection of localized (Korean) AWS AI/ML workshop materials for hands-on labs. - aws-samples/aws-ai-ml-workshop-kr
github.com

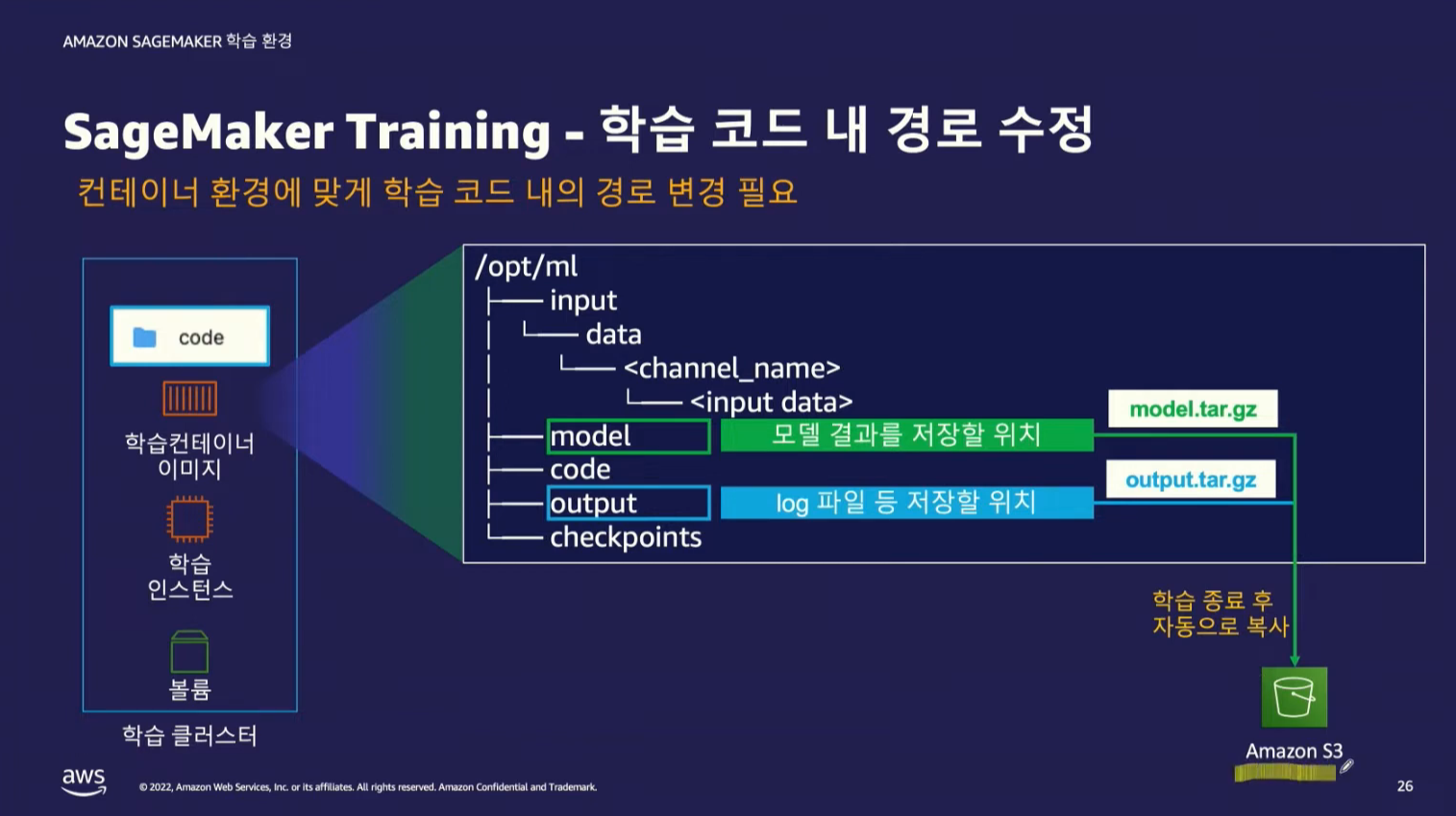
SageMaker에서는 코드를 생성하는 쥬피터 환경에서 학습을 시켜도 되지만, 코드를 생성하는 환경에서 인스턴스의 크기가 크면 비용이 많이 발생하기 때문에 학습할 코드에 대해서만 다른 인스턴스에서 학습이 가능하다.
Training 단계
해당 코드는 학습시킬 인스턴스의 크기를 지정 하는 것이다.
estimator = XGBoost(
entry_point="xgboost_starter_script.py",
source_dir='src',
output_path=output_path,
code_location=code_location,
hyperparameters=hyperparameters,
role=role,
sagemaker_session=sagemaker_session,
instance_count=instance_count,
instance_type=instance_type,
framework_version="1.3-1",
max_run=max_run,
use_spot_instances=use_spot_instances, # spot instance 활용
max_wait=max_wait,
)
| 파라미터 | 설명 |
| entry_point | SageMaker에서 실행할 학습 스크립트의 파일 경로 |
| source_dir | 학습 스크립트와 관련된 추가 파일이 있는 디렉토리의 경로 |
| output_path | 학습 작업의 결과물인 모델 아티팩트가 저장될 S3 버킷의 경로 |
| code_location | 학습 코드가 업로드되는 S3 버킷의 경로 |
| hyperparameters | 모델 학습을 위한 하이퍼파라미터 설정 |
| role | SageMaker 리소스에 액세스할 수 있는 IAM 역할 |
| sagemaker_session | SageMaker 작업을 수행하는 데 사용되는 세션 |
| instance_count | 학습에 사용할 EC2 인스턴스의 수 |
| instance_type | 학습에 사용할 EC2 인스턴스의 유형 |
| framework_version | 사용할 프레임워크 버전 |
| max_run | 학습 작업의 최대 실행 시간(초) |
| use_spot_instances | Spot Instance를 사용하여 학습을 실행할지 여부 |
| max_wait | Spot Instance 요청을 대기하는 최대 시간(초) |
estimator.fit(inputs = {'inputdata': inputs},
wait=False)
Experiments 단계
| 메소드 또는 인자 설명 | 설명 |
| estimator.fit() | SageMaker 추정기(estimator)에서 제공하는 메서드로, 주어진 입력 데이터를 사용하여 모델을 학습시킵니다. 학습이 완료되면 학습된 모델 아티팩트가 지정된 S3 버킷 경로에 저장됩니다. |
| inputs | fit() 메서드의 입력으로 사용되는 딕셔너리입니다. 딕셔너리 키는 입력 채널의 이름을 나타내며, 값은 해당 입력 채널에 대한 데이터 위치를 나타냅니다. 여기서 'inputdata'는 입력 채널의 이름이고, inputs는 데이터 위치를 나타냅니다. |
| wait | 학습 작업이 완료될 때까지 메서드가 블록되어야 하는지 여부를 나타내는 부울 값입니다. False로 설정되면 학습 작업이 백그라운드에서 비동기적으로 실행됩니다. 기본값은 True입니다. |
def create_experiment(experiment_name):
try:
sm_experiment = Experiment.load(experiment_name)
except:
sm_experiment = Experiment.create(experiment_name=experiment_name)
def create_trial(experiment_name):
create_date = strftime("%m%d-%H%M%s")
sm_trial = Trial.create(trial_name=f'{experiment_name}-{create_date}',
experiment_name=experiment_name)
job_name = f'{sm_trial.trial_name}'
return job_name
create_experiment(experiment_name)
job_name = create_trial(experiment_name)
estimator.fit(inputs = {'inputdata': inputs},
job_name = job_name,
experiment_config={
'TrialName': job_name,
'TrialComponentDisplayName': job_name,
},
wait=False)
| 함수 또는 변수 | 설명 |
| create_experiment() | 주어진 실험 이름(experiment_name)을 사용하여 SageMaker 실험을 만듭니다. 만약 해당 이름의 실험이 이미 존재한다면, 해당 실험을 로드합니다. 실험이 존재하지 않는 경우 새로운 실험을 생성합니다. |
| create_trial() | 주어진 실험 이름(experiment_name)을 기반으로 새로운 SageMaker 시험을 만듭니다. 시험의 이름은 실험 이름과 생성 날짜로 구성됩니다. 생성된 시험의 이름을 반환합니다. |
| experiment_name | 실험의 이름을 지정하는 변수로, 실험과 시험의 이름으로 사용됩니다. |
| job_name | 시험의 이름을 나타내는 변수로, 모델 학습 작업의 고유 식별자로 사용됩니다. |
| estimator.fit() | SageMaker 추정기(estimator)에서 제공하는 메서드로, 주어진 입력 데이터를 사용하여 모델을 학습시킵니다. 학습이 완료되면 학습된 모델 아티팩트가 지정된 S3 버킷 경로에 저장됩니다. 이때, 실험과 시험을 관련시키기 위해 experiment_config 매개변수를 통해 시험의 이름과 트라이얼 컴포넌트 디스플레이 이름을 설정합니다. |
| inputs | fit() 메서드의 입력으로 사용되는 딕셔너리입니다. 딕셔너리 키는 입력 채널의 이름을 나타내며, 값은 해당 입력 채널에 대한 데이터 위치를 나타냅니다. 여기서 'inputdata'는 입력 채널의 이름이고, inputs는 데이터 위치를 나타냅니다. |
| experiment_config | 모델 학습 작업을 실험과 관련시키기 위한 구성입니다. 이 구성에는 실험 이름과 시험의 이름을 설정합니다. 실험 및 시험 이름은 시험의 모니터링 및 추적을 용이하게 합니다. |


# sagemaker/sm-special-webinar/lab_1_training/src/xgboost_starter_script.py
###########################################################################################################################
'''
훈련 코드는 크게 아래와 같이 구성 되어 있습니다.
- 커맨드 인자로 전달된 변수 내용 확인
- 훈련 데이터 로딩
- xgboost의 cross-validation(cv) 로 훈련
- 훈련 및 검증 데이터 세트의 roc-auc 값을 metrics_data 에 저장
- 모델 훈련시 생성되는 지표(예: loss 등)는 크게 두가지 방식으로 사용 가능
- 클라우드 워치에서 실시간으로 지표 확인
- 하이퍼 파라미터 튜닝(HPO) 에서 평가 지표로 사용 (예: validation:roc-auc)
- 참조 --> https://docs.amazonaws.cn/en_us/sagemaker/latest/dg/training-metrics.html
- 참조: XGBoost Framework 에는 이미 디폴트로 정의된 metric definition이 있어서, 정의된 규칙에 따라서 모델 훈련시에 print() 를 하게 되면,
metric 이 클라우드 워치 혹은 HPO에서 사용이 가능
Name Regex
validation:auc .*\[[0-9]+\].*#011validation-auc:([-+]?[0-9]*\.?[0-9]+(?:[eE][-+]?[0-9]+)?).*
train:auc .*\[[0-9]+\].*#011train-auc:([-+]?[0-9]*\.?[0-9]+(?:[eE][-+]?[0-9]+)?).*
실제 코드에 위의 Regex 형태로 print() 반영
print(f"[0]#011train-auc:{train_auc_mean}")
print(f"[1]#011validation-auc:{validation_auc_mean}")
- 훈련 성능을 나타내는 지표를 저장 (metrics.json)
- 훈련이 모델 아티펙트를 저장
'''
###########################################################################################################################
import os
import sys
import pickle
import xgboost as xgb
import argparse
import pandas as pd
import json
import pandas as pd
pd.options.display.max_rows=20
pd.options.display.max_columns=10
def train_sagemaker(args):
if os.environ.get('SM_CURRENT_HOST') is not None:
args.train_data_path = os.environ.get('SM_CHANNEL_INPUTDATA')
args.model_dir = os.environ.get('SM_MODEL_DIR')
args.output_data_dir = os.environ.get('SM_OUTPUT_DATA_DIR')
return args
def main():
parser = argparse.ArgumentParser()
###################################
## 커맨드 인자 처리
###################################
# Hyperparameters are described here
parser.add_argument('--scale_pos_weight', type=int, default=50)
parser.add_argument('--num_round', type=int, default=999)
parser.add_argument('--max_depth', type=int, default=3)
parser.add_argument('--eta', type=float, default=0.2)
parser.add_argument('--objective', type=str, default='binary:logistic')
parser.add_argument('--nfold', type=int, default=5)
parser.add_argument('--early_stopping_rounds', type=int, default=10)
parser.add_argument('--train_data_path', type=str, default='../../data/dataset')
# SageMaker specific arguments. Defaults are set in the environment variables.
parser.add_argument('--model-dir', type=str, default='../model')
parser.add_argument('--output-data-dir', type=str, default='../output')
args = parser.parse_args()
## Check Training Sagemaker
args = train_sagemaker(args)
###################################
## 데이터 세트 로딩 및 변환
###################################
data = pd.read_csv(f'{args.train_data_path}/train.csv')
train = data.drop('fraud', axis=1)
label = pd.DataFrame(data['fraud'])
dtrain = xgb.DMatrix(train, label=label)
###################################
## 하이퍼파라미터 설정
###################################
params = {'max_depth': args.max_depth, 'eta': args.eta, 'objective': args.objective, 'scale_pos_weight': args.scale_pos_weight}
num_boost_round = args.num_round
nfold = args.nfold
early_stopping_rounds = args.early_stopping_rounds
###################################
## Cross-Validation으로 훈련하여, 훈련 및 검증 메트릭 추출
###################################
cv_results = xgb.cv(
params = params,
dtrain = dtrain,
num_boost_round = num_boost_round,
nfold = nfold,
early_stopping_rounds = early_stopping_rounds,
metrics = ('auc'),
stratified = True, # 레이블 (0,1) 의 분포에 따라 훈련 , 검증 세트 분리
seed = 0
)
###################################
## 훈련 및 검증 데이터 세트의 roc-auc 값을 metrics_data 에 저장
###################################
print("cv_results: ", cv_results)
# for i in cv_results.index:
# train_auc_mean = cv_results['train-auc-mean'][i]
# train_auc_std = cv_results['train-auc-std'][i]
# test_auc_mean = cv_results['test-auc-mean'][i]
# test_auc_std = cv_results['test-auc-std'][i]
# print(f" train_auc_mean : {train_auc_mean}, train_auc_std : {train_auc_std}, test_auc_mean : {test_auc_mean}, test_auc_std : {test_auc_std}, ")
# Select the best score
print(f"[0]#011train-auc:{cv_results.iloc[-1]['train-auc-mean']}")
print(f"[1]#011validation-auc:{cv_results.iloc[-1]['test-auc-mean']}")
metrics_data = {
'classification_metrics': {
'validation:auc': { 'value': cv_results.iloc[-1]['test-auc-mean']},
'train:auc': {'value': cv_results.iloc[-1]['train-auc-mean']}
}
}
###################################
## 오직 훈련 데이터 만으로 훈련하여 모델 생성
###################################
model = xgb.train(params=params, dtrain=dtrain, num_boost_round=len(cv_results))
###################################
## 모델 아티펙트 및 훈련/검증 지표를 저장
###################################
# Save the model to the location specified by ``model_dir``
os.makedirs(args.output_data_dir, exist_ok=True)
os.makedirs(args.model_dir, exist_ok=True)
metrics_location = args.output_data_dir + '/metrics.json'
model_location = args.model_dir + '/xgboost-model'
with open(metrics_location, 'w') as f:
json.dump(metrics_data, f)
model.save_model(model_location)
if __name__ == '__main__':
main()

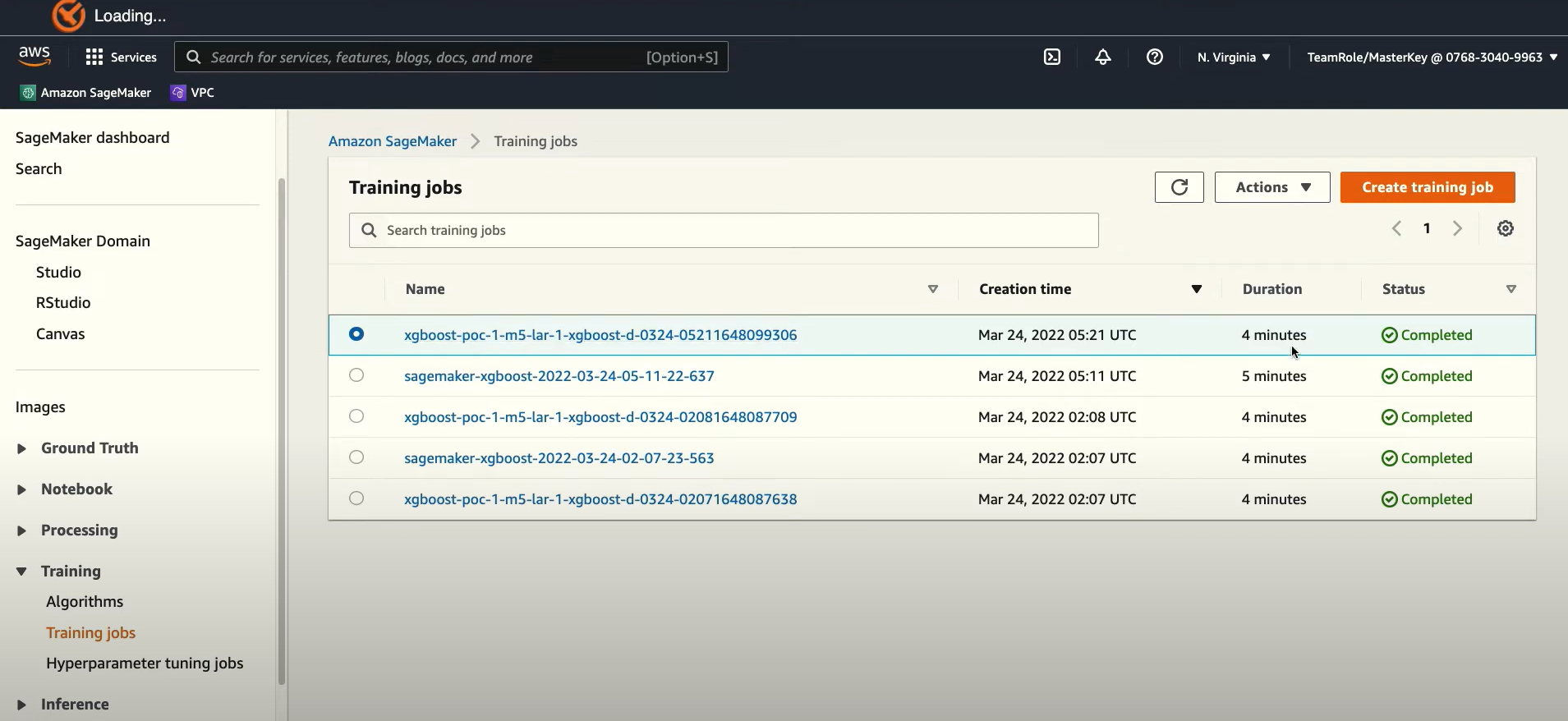
학습된 결과 중 이름의 이미
xgboost-poc-1-m5-lar-1-xgboost-d-0324-05211648099306
| xgboost-poc-1 | 이 |
| m5-lar | 인스턴스 크기 |
| 1 | 인스턴스 수 |
| xgboost | 알고리즘 명 |
| d | on-demand 로 실행 |
| 0324 | 3월 24일 실행 |
| 05211648099306 | 잘 모르겠음 |
Processing 단계

input_data에는 학습할 데이터 뿐만 아니라 학습된 데이터 model.tar.gz 에 대한 것도 있다.
from sagemaker.processing import FrameworkProcessor
from sagemaker.processing import ProcessingInput, ProcessingOutput
instance_count = 1
instance_type = "ml.m5.large"
# instance_type = 'local'
script_eval = FrameworkProcessor(
XGBoost,
framework_version="1.3-1",
role=role,
instance_type=instance_type,
instance_count=instance_count
)
artifacts_dir = estimator.model_data
s3_test_path = data_path + '/test.csv'
detect_outputpath = f's3://{bucket}/xgboost/processing'
source_dir='src'
if instance_type == 'local':
from sagemaker.local import LocalSession
from pathlib import Path
sagemaker_session = LocalSession()
sagemaker_session.config = {'local': {'local_code': True}}
source_dir = f'{Path.cwd()}/src'
s3_test_path=f'../data/dataset/test.csv'
create_experiment(experiment_name)
job_name = create_trial(experiment_name)
script_eval.run(
code="evaluation.py",
source_dir=source_dir,
inputs=[ProcessingInput(source=s3_test_path, input_name="test_data", destination="/opt/ml/processing/test"),
ProcessingInput(source=artifacts_dir, input_name="model_weight", destination="/opt/ml/processing/model")
],
outputs=[
ProcessingOutput(source="/opt/ml/processing/output", output_name='evaluation', destination=detect_outputpath + "/" + job_name),
],
job_name=job_name,
experiment_config={
'TrialName': job_name,
'TrialComponentDisplayName': job_name,
},
wait=False
)
script_eval.latest_job.wait()| 코드 또는 변 | 설명 |
| FrameworkProcessor | SageMaker에서 제공하는 프레임워크 프로세서를 초기화합니다. |
| instance_count | 프로세싱 작업을 실행할 인스턴스의 수를 지정합니다. |
| instance_type | 프로세싱 작업을 실행할 인스턴스의 유형을 지정합니다. |
| script_eval | SageMaker에서 제공하는 프레임워크 프로세서를 초기화합니다. |
| artifacts_dir | 모델 아티팩트가 저장된 S3 버킷 경로를 지정합니다. |
| s3_test_path | 모델 평가에 사용될 테스트 데이터의 S3 경로를 지정합니다. |
| detect_outputpath | 프로세싱 작업의 출력이 저장될 S3 버킷 경로를 지정합니다. |
| create_experiment(experiment_name) | 주어진 실험 이름으로 SageMaker 실험을 생성합니다. 실험이 이미 존재하는 경우 해당 실험을 로드합니다. 실험이 없는 경우 새로운 실험을 생성합니다. |
| create_trial(experiment_name) | 주어진 실험 이름을 기반으로 새로운 SageMaker 시험을 생성합니다. 시험의 이름은 실험 이름과 생성 날짜로 구성됩니다. 생성된 시험의 이름을 반환합니다. |
| script_eval.run() | 모델 평가 작업을 실행합니다. 이때, 입력 데이터와 출력 데이터의 경로, 작업 이름, 실험 구성 등을 지정합니다. wait=False로 설정하여 작업이 비동기적으로 실행됩니다. |
| script_eval.latest_job.wait() | 실행된 작업이 완료될 때까지 대기합니다. |
# sagemaker/sm-special-webinar/lab_1_training/src/evaluation.py
import json
import pathlib
import pickle
import tarfile
import joblib
import numpy as np
import pandas as pd
import argparse
import os
from sklearn.metrics import classification_report
from sklearn.metrics import confusion_matrix
import subprocess, sys
subprocess.check_call([sys.executable, '-m', 'pip', 'install', 'xgboost'])
import xgboost
from sklearn.metrics import mean_squared_error
import logging
import logging.handlers
def _get_logger():
'''
로깅을 위해 파이썬 로거를 사용
# https://stackoverflow.com/questions/17745914/python-logging-module-is-printing-lines-multiple-times
'''
loglevel = logging.DEBUG
l = logging.getLogger(__name__)
if not l.hasHandlers():
l.setLevel(loglevel)
logging.getLogger().addHandler(logging.StreamHandler(sys.stdout))
l.handler_set = True
return l
logger = _get_logger()
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--base_dir', type=str, default= "/opt/ml/processing")
parser.add_argument('--model_path', type=str, default= "/opt/ml/processing/model/model.tar.gz")
parser.add_argument('--test_path', type=str, default= "/opt/ml/processing/test/test.csv")
parser.add_argument('--output_evaluation_dir', type=str, default="/opt/ml/processing/output")
# parse arguments
args = parser.parse_args()
logger.info("#############################################")
logger.info(f"args.model_path: {args.model_path}")
logger.info(f"args.test_path: {args.test_path}")
logger.info(f"args.output_evaluation_dir: {args.output_evaluation_dir}")
model_path = args.model_path
test_path = args.test_path
output_evaluation_dir = args.output_evaluation_dir
base_dir = args.base_dir
# Traverse all files
logger.info(f"****** All folder and files under {base_dir} ****** ")
for file in os.walk(base_dir):
logger.info(f"{file}")
logger.info(f"************************************************* ")
with tarfile.open(model_path) as tar:
tar.extractall(path=".")
model = xgboost.XGBRegressor()
model.load_model("xgboost-model")
logger.info(f"model is loaded")
df = pd.read_csv(test_path)
logger.info(f"test df sample \n: {df.head(2)}")
# y_test = df.iloc[:, 0].astype('int').to_numpy()
y_test = df.iloc[:, 0].astype('int')
df.drop(df.columns[0], axis=1, inplace=True)
# X_test = xgboost.DMatrix(df.values)
X_test = df.values
predictions_prob = model.predict(X_test)
# if predictions_prob is greater than 0.5, it is 1 as a fruad, otherwise it is 0 as a non-fraud
threshold = 0.5
predictions = [1 if e >= 0.5 else 0 for e in predictions_prob ]
# print("y_test: ", y_test)
# print("y_test length: ", len(y_test))
# print("predctions length: ", len(predictions))
# print("predctions: ", predictions)
# print("predictions: ", predictions)
# logging.info(f"{classification_report(y_true=y_test, y_pred = predictions)}")
print(f"{classification_report(y_true=y_test, y_pred = predictions)}")
cm = confusion_matrix(y_true= y_test, y_pred= predictions)
print(cm)
mse = mean_squared_error(y_test, predictions)
std = np.std(y_test - predictions)
report_dict = {
"regression_metrics": {
"mse": {
"value": mse,
"standard_deviation": std
},
},
}
pathlib.Path(output_evaluation_dir).mkdir(parents=True, exist_ok=True)
evaluation_path = f"{output_evaluation_dir}/evaluation.json"
with open(evaluation_path, "w") as f:
f.write(json.dumps(report_dict))
logger.info(f"evaluation_path \n: {evaluation_path}")
logger.info(f"report_dict \n: {report_dict}")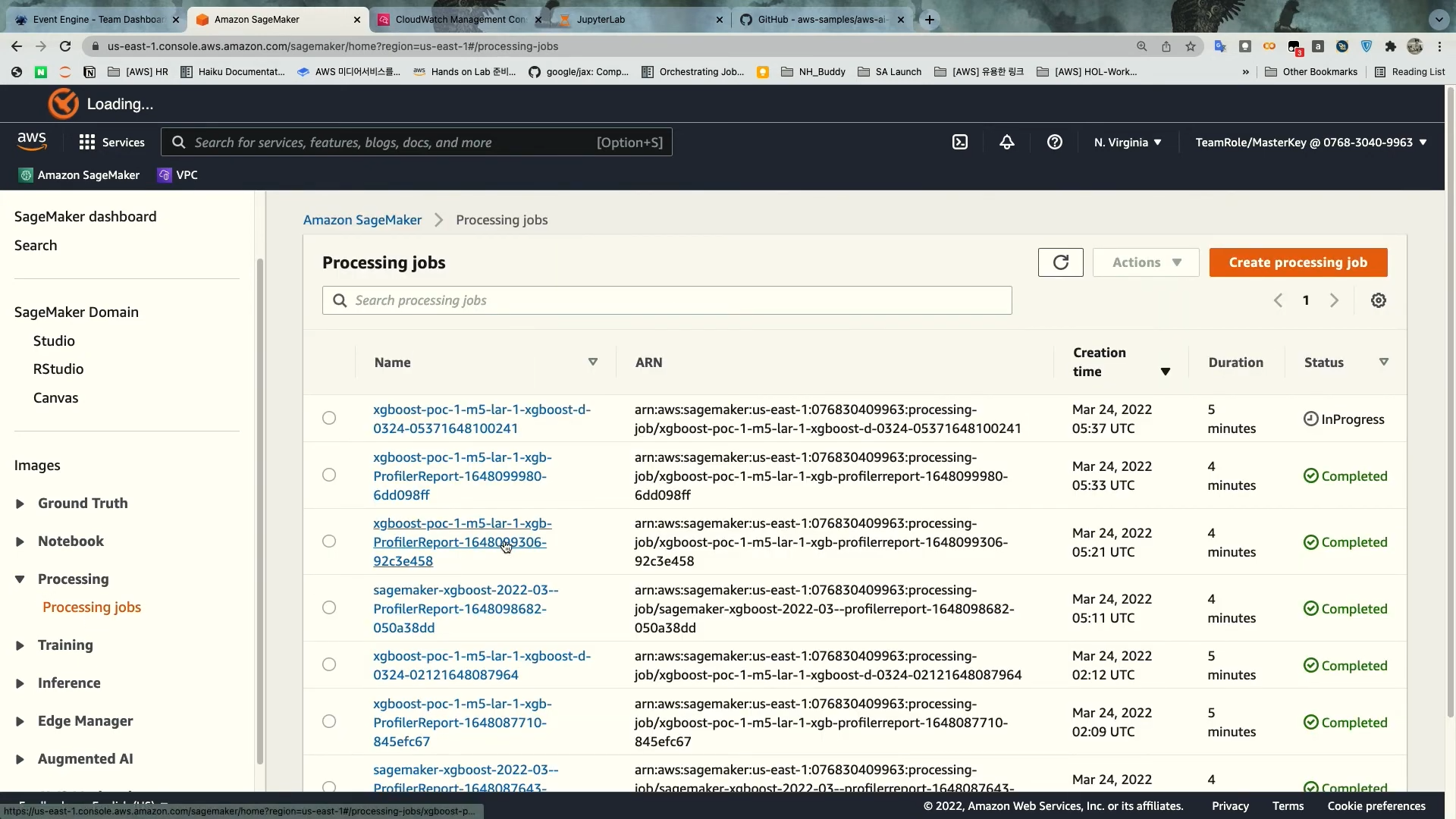
Experiments 이후 output 내용



Processing 이후 output 내용
